快速搭建本地 LLM 推理环境
部署
安装Ollama
Ollama简单来说,是一个基于Go 语言开发的简单易用的本地大语言模型运行框架。对于 Ollama 的基本部署都是很傻瓜化的,非常简单。在官方平台上找到对应的命令下载安装就行了,唯一需要注意的是网络情况。
-
进入到官网页面https://ollama.com/
-
找到对应的平台进行下载,这里我的是以Linux为例子
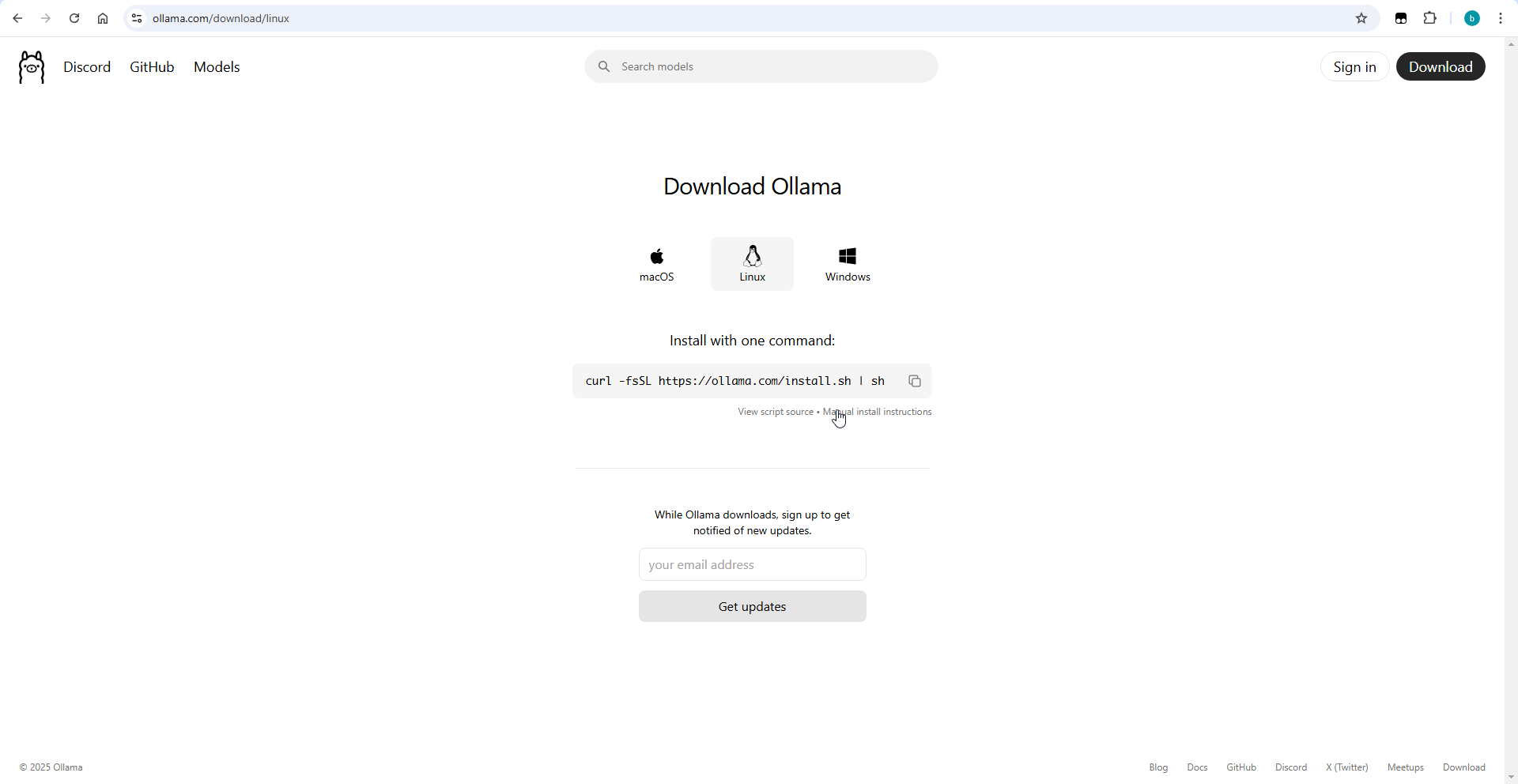
-
复制其中的命令,到终端粘贴
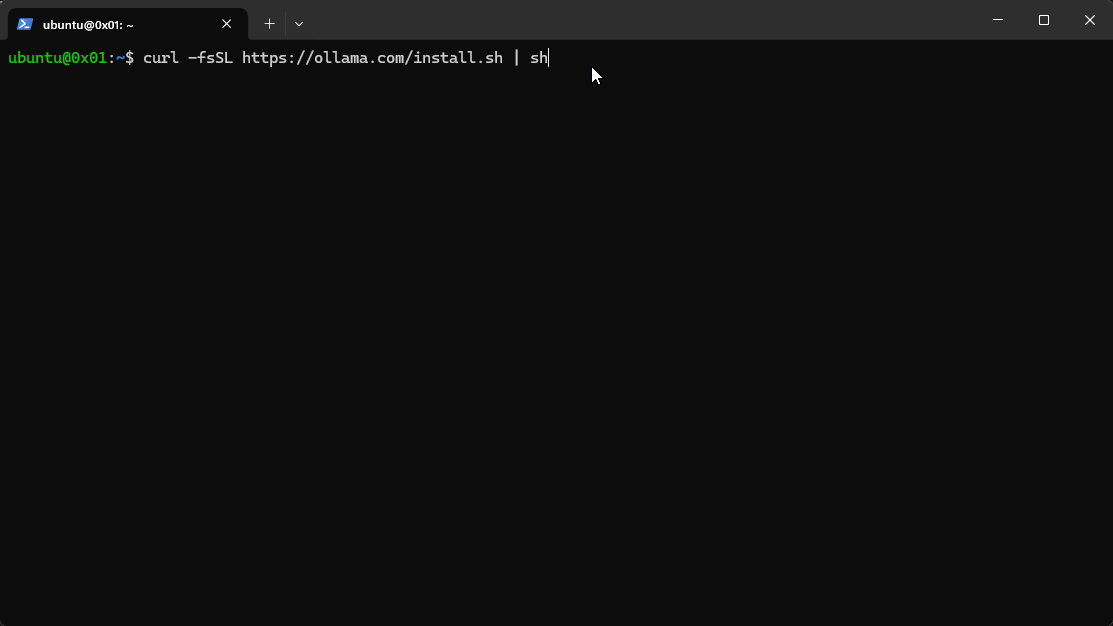
-
如何分享给别人使用,以特定的 IP 和端口启动
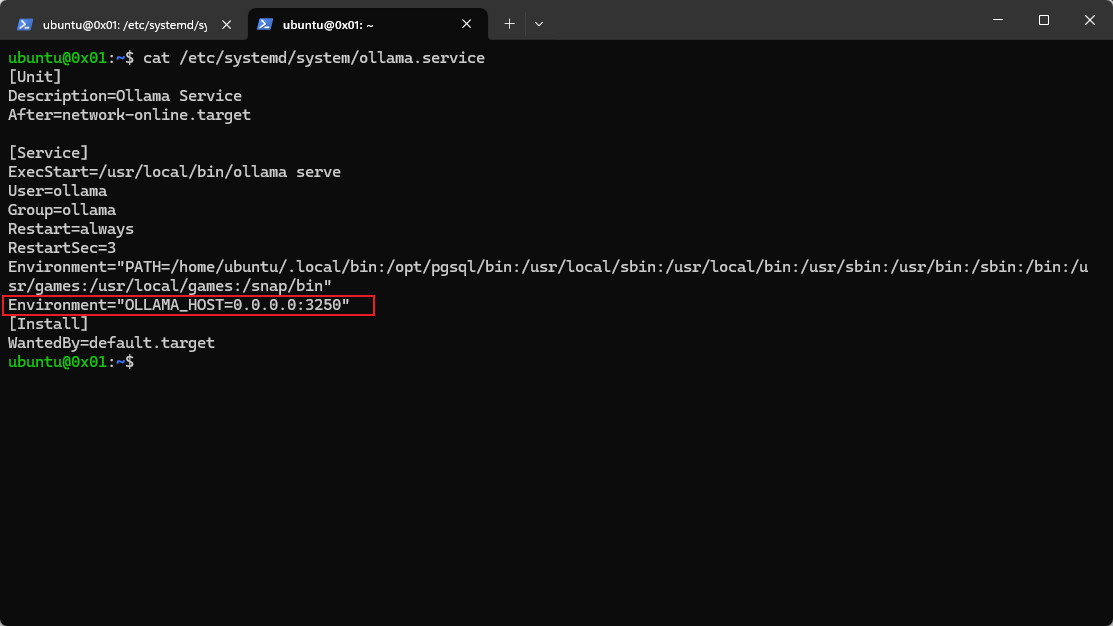
-
已经以特定的 IP 和端口启动之后,如何重新下载新的模型
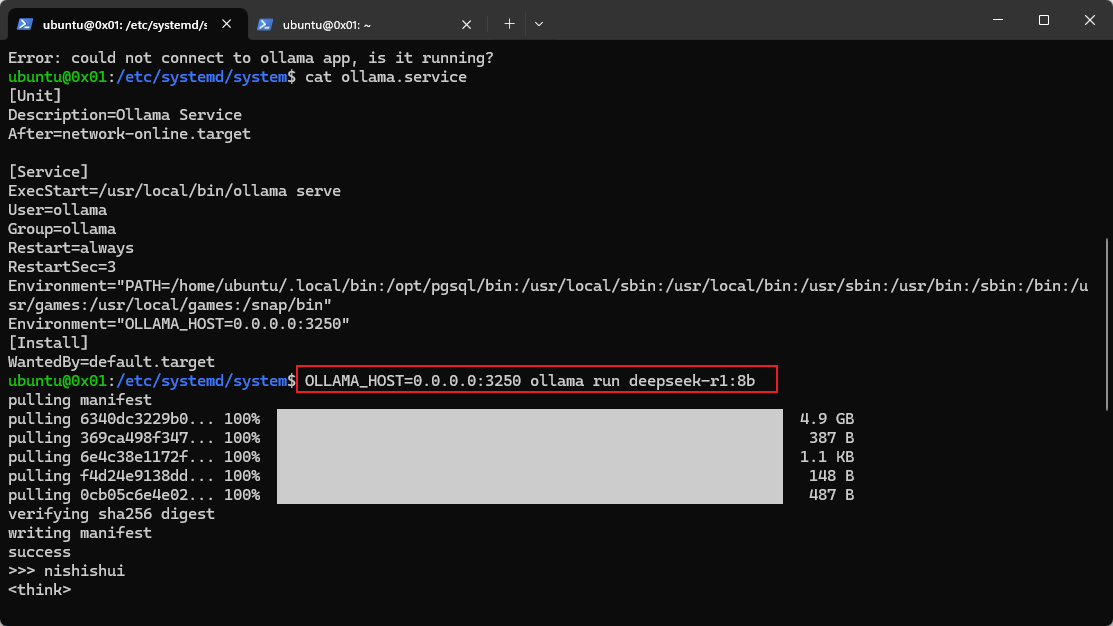
-
下载向量化模型
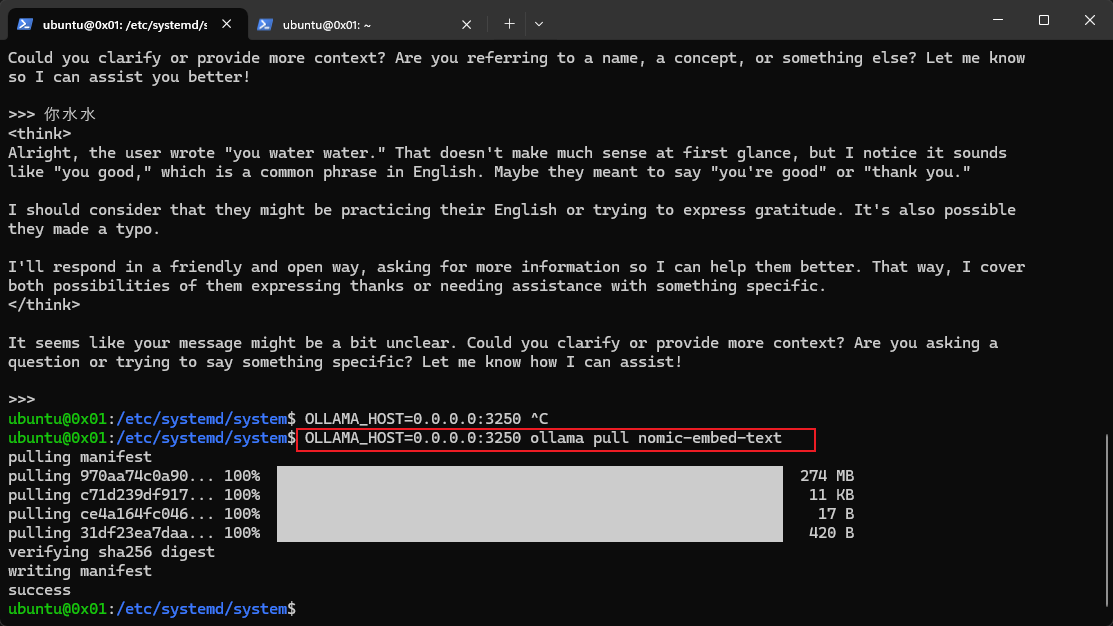
-
查看当前的 Ollama 服务运行是否正常
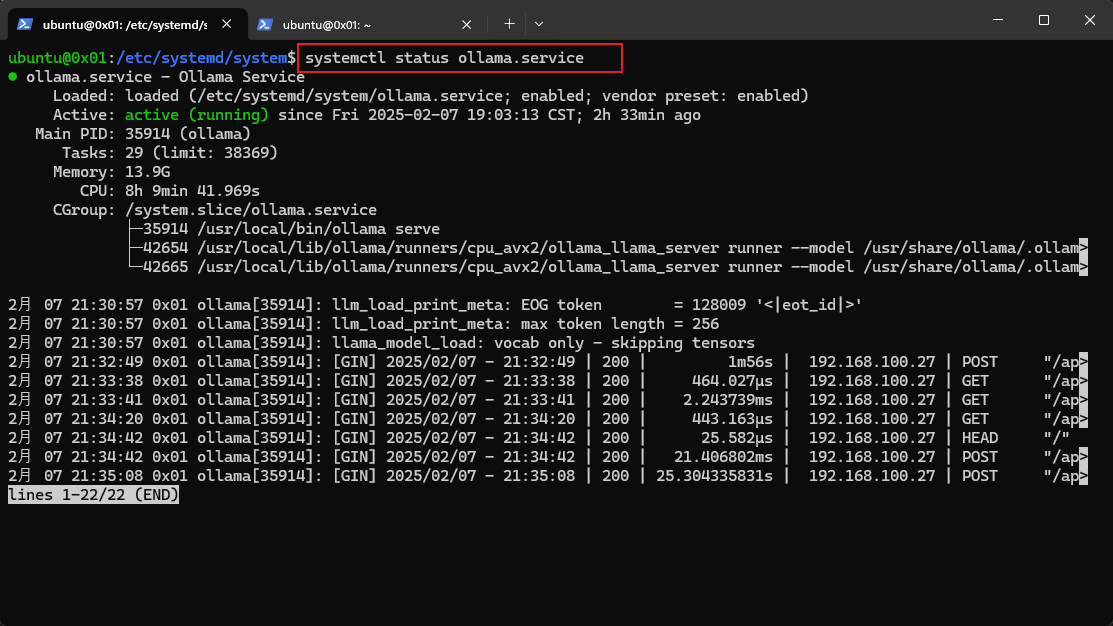
问题记录
在欧拉20.03的环境中直接执行 curl -fsSL https://ollama.com/install.sh | sh 报错,报错信息如下所示:

最后发现是默认的curl使用的openssl的版本较老,和本地的已有openssl不匹配了。

解决的办法也很简单,重新更新一个新的curl,使用yum update curl,如果更新的没有效果,就使用源码重新编译一个,具体编译的方式如下:
# 下载最新版本的 curl
wget https://curl.se/download/curl-8.6.0.tar.gz
tar -xvzf curl-8.6.0.tar.gz
cd curl-8.6.0
# 编译和安装
./configure --with-openssl
make
sudo make install
编译完成之后如果不生效,重新退出当前的shell,再打开一个新的就即可生效;或者执行source ~/.bashrc来使之生效。
Anything LLM

Anything LLM 是这样介绍自己的。https://anythingllm.com/
Everything great about AI in one desktop application.Chat with docs, use AI Agents, and more - full locally and offline.
桌面版本
桌面版本的只能单机使用,适合个人。
docker版本
docker版本的可以共享给其他人一起使用,适合团队。 注意:docker版本的安装官方说明中有几个前提条件,详细的可以从这个链接查看https://docs.anythingllm.com/installation-docker/local-docker:
docker的版本必须大于18.03
安装步骤如下所示,我这里新环境,从头开始,如果在你安装的过程中某些已经安装好了的则不必再重新安装,过程中遇到的问题我也会详细的说明原因及解决办法。 我安装的环境为欧拉20.03。
安装yarn和npm
安装nvm
直接将下面的命令复制到终端执行,执行完成后重新加载下环境变量source ~/.bashrc
curl -o- https://raw.githubusercontent.com/nvm-sh/nvm/v0.40.1/install.sh | bash```
通过nvm来安装node
nvm install 20
通过npm安装yarn
npm install yarn
安装docker
安装docker,这里直接使用命令安装即可。
yum install docker
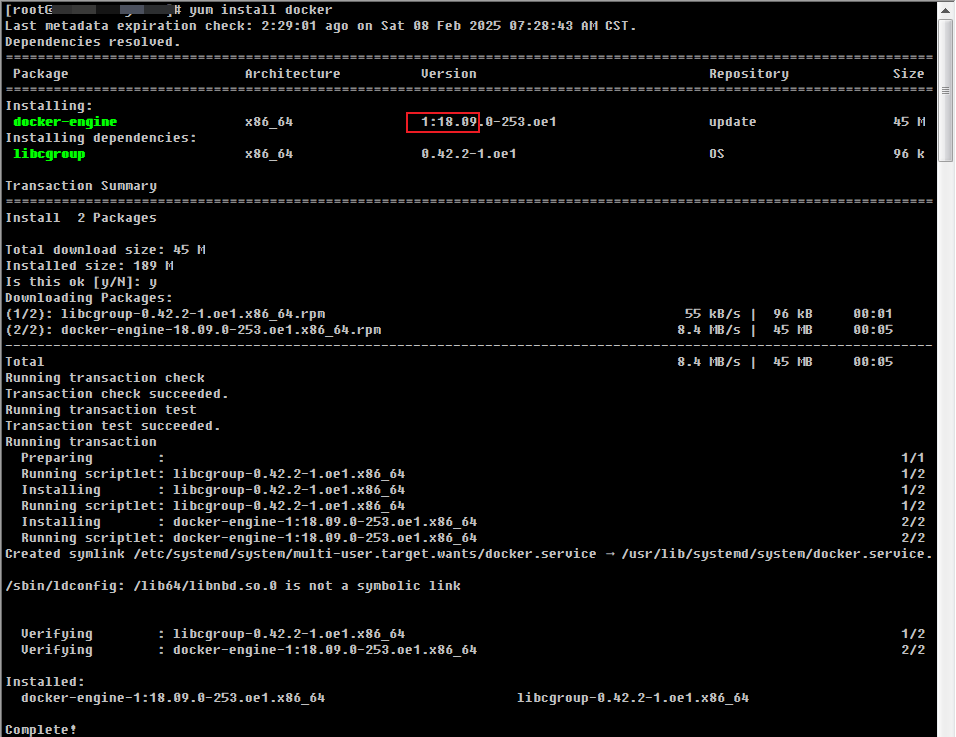
安装完成之后,docker是以后台服务的形式启动的,我们可以在上述的截图中看到如下输出
Created symlink /etc/systemd/system/multi-user.target.wants/docker.service → /usr/lib/systemd/system/docker.service.,
这个就是docker服务启动的配置文件,由于国内网络环境的原因,直接拉取镜像的时候会失败,所以我们需要修改这个配置文件增加代理。
打开这个文件(/usr/lib/systemd/system/docker.service)并编辑,添加如下截图所示内容,具体的内容要根据你自己的实际情况进行修改。
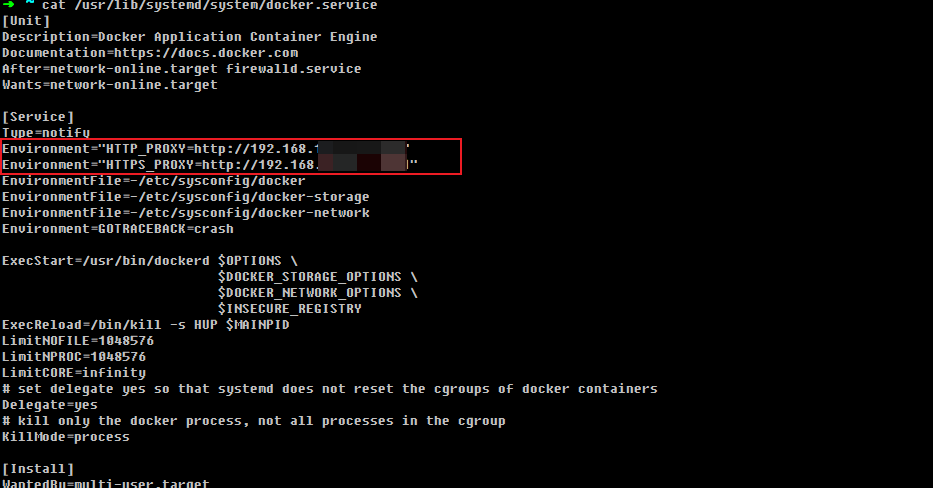
修改完成之后再执行systemctl daemon-reload重新加载服务,再执行systemctl restart docker.service重启docker服务。
拉取最近的docker镜像,依然是使用命令安装。
docker pull mintplexlabs/anythingllm
如果你再拉取的时候遇到了如下的错误,说明你的网络代理还是没有配置好。有一点需要注意的是,上述安装的docker是以daemon服务的方式启动的,所以你直接在终端中使用export或者set设置的环境变量是不起作用的,必须要在服务的启动配置文件里面设置才行。

启动
由于是团队访问,所以再官方命令的基础上加入了HOST参数,其他不变。
export STORAGE_LOCATION=$HOME/anythingllm && \
mkdir -p $STORAGE_LOCATION && \
touch "$STORAGE_LOCATION/.env" && \
docker run -d -p 3001:3001 \
--cap-add SYS_ADMIN \
-v ${STORAGE_LOCATION}:/app/server/storage \
-v ${STORAGE_LOCATION}/.env:/app/server/.env \
-e STORAGE_DIR="/app/server/storage" \
-e HOST="0.0.0.0" \
mintplexlabs/anythingllm
错误记录
这里启动的时候遇到一个问题SQLite database error unable to open database file: ../storage/anythingllm.db,通过执行chmod -R 777 $HOME/anythingllm来解决。
查看是否启动成功

数据目录结构
安装完成之后,我们可以在上述配置的$STORAGE_LOCATION这个目录下查看整个anythingllvm的数据结构。
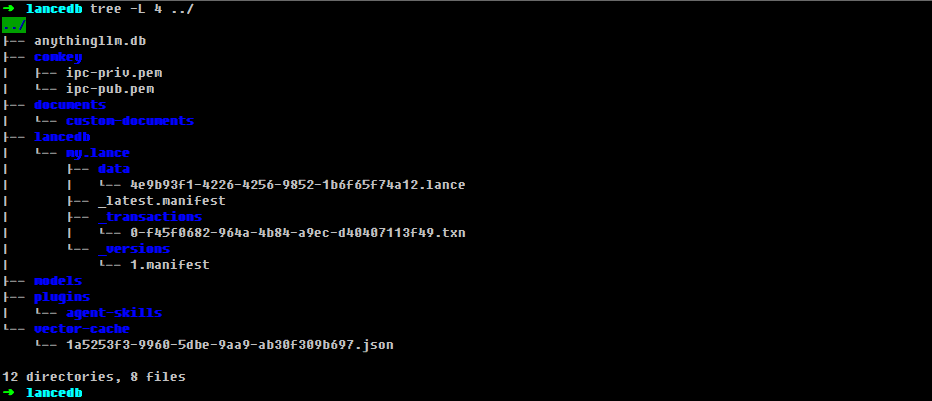
配置
经过上述的安装步骤后,我们在浏览器输入http://服务器的ip地址:3001进入到AnythingLLM的配置或者登录界面
打开配置界面
点击左下角的小扳手打开配置界面
模型配置
重点关注三个界面,LLM大模型,向量数据库,嵌入模型
在大模型界面,填入ollama启动的地址,上面的模型列表就会自动加载出当前系统已经存在的模型。
向量数据库界面来选择对应的向量数据库,默认是LanceDB,当然也可以根据需要设置其他的。
Embedder首选项界面用来选择对应的嵌入模型,ollama默认的为Nomic Embed,这个也需要使用ollama pull nomic-embed-text来下载
多用户
向量数据库
以下是一些常见的向量数据库:
- LanceDB
- Astra DB
- Pinecone
- Chroma
- Weaviate
- Qdrant
- Milvus
- Zilliz
- PGVector(PostgreSQL)
RAG(Retrieval-Augmented Generation)
RAG,即“检索增强生成”,是一种结合了信息检索和生成模型的自然语言处理(NLP)方法。RAG 模型通常由两个主要部分组成:检索器和生成器。
-
检索器(Retriever):该部分负责从一个大型文档集合中检索出与输入查询相关的文档或信息。检索器通常使用向量化技术将文本数据转化为向量,以便能够快速相似度匹配。
-
生成器(Generator):在检索器找到相关文档后,生成器使用这些文档的内容来生成最终的响应。生成器通常是基于变换器(Transformer)架构的语言模型,如 BERT、GPT 等。
通过这种组合,RAG 模型能够生成更为准确和相关的回答,因为它不仅依赖于模型的预训练知识,还能利用实时检索到的信息。
嵌入、数据向量化、嵌入模型、向量数据库的关系
嵌入(Embedding):
- 嵌入是将高维数据(如文本、图像等)映射到低维向量空间的过程。通过嵌入,数据的语义信息可以在向量空间中保持相对位置,使得相似的内容在向量空间中靠近。
- 嵌入可以用于多种任务,如分类、聚类、推荐系统等。
数据向量化(Vectorization):
- 数据向量化是将原始数据(如文本、图像等)转换为向量的过程。这个过程通常涉及将数据转换为数值格式,以便计算机可以处理。
- 向量化的结果就是嵌入,通常使用特定的嵌入模型来生成这些向量。
嵌入模型(Embedding Model):
- 嵌入模型是用于生成嵌入的算法或模型。这些模型可以是预训练的(如 Word2Vec、GloVe、BERT、Sentence Transformers 等),也可以是根据特定数据集训练的。
- 嵌入模型的目标是捕捉数据的语义特征,使得相似的数据在向量空间中距离较近。
向量数据库(Vector Database):
- 向量数据库是专门用于存储和检索向量数据的数据库。它们优化了相似度搜索,以便快速找到与给定向量相似的向量。
- 向量数据库通常使用高效的索引结构(如 HNSW、Annoy、FAISS 等)来加速检索过程。它们可以与嵌入模型结合使用,以实现高效的 RAG 系统。
关系总结
- 嵌入是通过嵌入模型将数据向量化的结果,表示数据在低维空间中的语义信息。
- 数据向量化是将原始数据转换为向量的过程,而嵌入模型是实现这一过程的工具。
- 向量数据库则用于存储这些向量并支持高效的相似度检索,通常与 RAG 系统中的检索器部分紧密结合。
嵌入是将数据(如文本、图像)通过嵌入模型转化为向量表示的过程,这些向量化的数据可以存储在向量数据库中,以便高效地进行相似性搜索和检索。
+---------------------+ +--------------------+ +--------------------+
| 原始文本数据 | ---> | 嵌入模型(如BERT) | ---> | 向量表示(低维向量)|
| (如:"猫在睡觉") | | (将文本转换为向量) | | (数字向量) |
+---------------------+ +--------------------+ +--------------------+
|
v
+-----------------------+
| 向量数据库(如FAISS)|
| (存储和索引向量) |
+-----------------------+
|
v
+----------------------+
| 相似度检索和匹配 |
| (根据向量计算相似度) |
+----------------------+
+-----------------------+ +---------------------+ +-------------------+ +---------------------+
| 用户查询文本 | ---> | 本地嵌入模型 (如BERT) | ---> | 向量化查询文本 | ---> | 向量数据库 (FAISS) |
| (如:什么是机器学习?) | | (将查询转换为向量) | | (低维向量表示) | | (存储文档的向量表示) |
+-----------------------+ +---------------------+ +-------------------+ +---------------------+
|
v
+-------------------------------+
| 向量检索与RAG (检索相关文档) |
| (通过相似度匹配找到相关文档) |
+-------------------------------+
|
v
+-------------------------------+
| 生成模型 (如GPT-3) |
| (基于检索到的内容生成答案) |
+-------------------------------+
|
v
+-------------------------------+
| 输出生成答案 |
| (回答用户查询) |
+-------------------------------+
版权声明: 如无特别声明,本文版权归 sshipanoo 所有,转载请注明本文链接。
(采用 CC BY-NC-SA 4.0 许可协议进行授权)
本文标题:《 Ollama 部署系列——本地安装 》
本文链接:http://localhost:3015/ai/ollama-deploy.html
本文最后一次更新为 天前,文章中的某些内容可能已过时!

你愿意为你喜欢的事情付出多少!

