AI 应用的标准化接口规范
介绍
MCP is an open protocol that standardizes how applications provide context to LLMs. Think of MCP like a USB-C port for AI applications. Just as USB-C provides a standardized way to connect your devices to various peripherals and accessories, MCP provides a standardized way to connect AI models to different data sources and tools.
Why MCP?
MCP helps you build agents and complex workflows on top of LLMs. LLMs frequently need to integrate with data and tools, and MCP provides:
- A growing list of pre-built integrations that your LLM can directly plug into
- The flexibility to switch between LLM providers and vendors
- Best practices for securing your data within your infrastructure
基础架构
At its core, MCP follows a client-server architecture where a host application can connect to multiple servers:
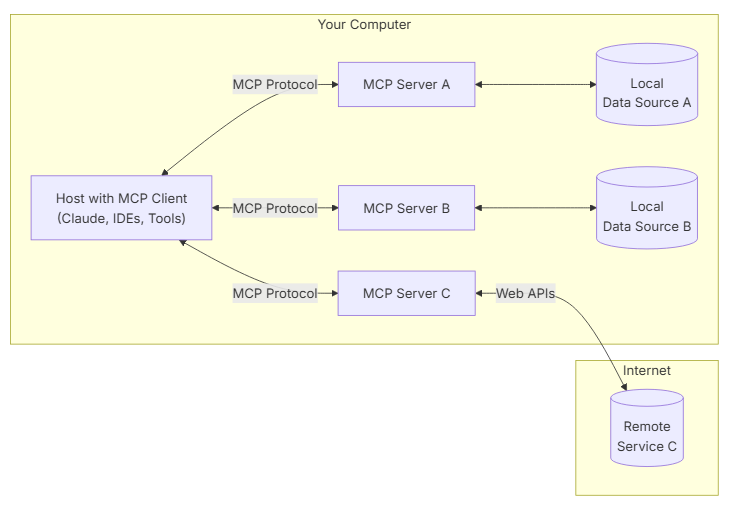
- MCP Hosts: Programs like Claude Desktop, IDEs, or AI tools that want to access data through MCP
- MCP Clients: Protocol clients that maintain 1:1 connections with servers
- MCP Servers: Lightweight programs that each expose specific capabilities through the standardized Model Context Protocol
- Local Data Sources: Your computer’s files, databases, and services that MCP servers can securely access
- Remote Services: External systems available over the internet (e.g., through APIs) that MCP servers can connect to
举几个通俗的例子来说明含义:
-
MCP Hosts: 就是运行在你电脑上的应用程序,比如说Claude Desktop,VS Code,AI助手等,他们希望可以通过MCP协议来访问数据。比如说: 你在用Claude Desktop,想让他帮你分析本地的excel的文件;或者你在Vscode里面,用一个AI插件来帮你读写文件代码文件;或者一个AI助手的应用,想访问你的本地数据库做智能问答。
-
MCP Clients: 和MCP服务器保持一对一连接的协议客户端,负责发起请求和接收数据。 比如说,Claude Desktop 里的“文件浏览”功能,就是一个 MCP Client,它和 MCP Server 建立连接,请求文件内容;或者说一个命令行工具, 通过MCP协议连接到本地的图片识别的服务,上传图片并获取识别结果。
-
MCP Servers: 轻量级的程序,每个都通过MCP协议暴露某一类能力(比如文件访问,数据库查询等)。比如说,一个MCP Server负责让外部程序读取你电脑上的文件,另外一个MCP Server负责让外部的程序访问本地的SQLite数据库。还有一个MCP server负责调用你电脑上的摄像头,返回拍摄的照片。
-
Local Data Sources: 你电脑上的各种数据资源,比如文件、数据库、服务等,MCP server可以完全访问他们。例如: 你的电脑里的所有文件,你本地与逆行的MYSQL或者SQLite数据库,电脑上的打印机,摄像头等硬件服务。
-
Remote Services: 通过互联网可以访问外部系统或者API,MCP Server也可以连接这些服务。 例如: 一个MCP Server连接到OpenAI的API,帮你调用GPT模型;连接到Google Drive API,帮你读写云端的文件。 甚至是连接到公司内部的RESTFul API,获取业务数据。
简单的总结一下就是:
- Host 是“想要用数据的应用”,比如 Claude Desktop、VS Code。
- Client 是“发起请求的协议客户端”,比如 Claude Desktop 里的某个功能模块。
- Server 是“提供具体能力的小服务”,比如文件访问、数据库访问等。
- Local Data Sources 是“你电脑上的数据资源”。
- Remote Services 是“互联网上的外部服务”。
一个简单的使用Python实现的mcp server的例子。
# server.py
from fastapi import FastAPI
from fastapi.responses import StreamingResponse, HTMLResponse
from mcp.server.fastmcp import FastMCP, Context
from mcp.types import (
TextContent
)
import asyncio
import uvicorn
import os
# Create an MCP server
mcp = FastMCP("Streamable DEMO")
app = FastAPI()
@app.get("/", response_class=HTMLResponse)
async def root():
html_path = os.path.join(os.path.dirname(__file__), "welcome.html")
with open(html_path, "r", encoding="utf-8") as f:
html_content = f.read()
return HTMLResponse(content=html_content)
async def event_stream(message: str):
for i in range(1, 4):
yield f"Processing file {i}/3...\n"
await asyncio.sleep(1)
yield f"Here's the file content: {message}\n"
@app.get("/stream")
async def stream(message: str = "hello"):
return StreamingResponse(event_stream(message), media_type="text/plain")
@mcp.tool(description="A tool that simulates file processing and sends progress notifications")
async def process_files(message: str, ctx: Context) -> TextContent:
files = [f"file_{i}.txt" for i in range(1, 4)]
for idx, file in enumerate(files, 1):
await ctx.info(f"Processing {file} ({idx}/{len(files)})...")
await asyncio.sleep(1)
await ctx.info("All files processed!")
return TextContent(type="text", text=f"Processed files: {', '.join(files)} | Message: {message}")
# calculator a plus b
@mcp.tool(description="A tool that adds two numbers")
async def add_numbers(a: int, b: int, ctx: Context) -> TextContent:
result = a + b
await ctx.info(f"Adding {a} and {b}, result: {result}")
return TextContent(type="text", text=f"Result of addition: {result}")
@mcp.tool(description="A tool that create task and returns its ID")
async def create_task(task_name: str, ctx: Context) -> TextContent:
task_id = f"task_{task_name}"
await ctx.info(f"Creating task with ID: {task_id}")
return TextContent(type="text", text=f"Task created with ID: {task_id}")
@mcp.tool(description="A tool that get weibo hot search")
async def get_weibo_hot_search(ctx: Context) -> TextContent:
import httpx
import re
url = "https://s.weibo.com/top/summary"
try:
async with httpx.AsyncClient(timeout=10, follow_redirects=True) as client:
resp = await client.get(url, headers={
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/138.0.0.0 Safari/537.36 Edg/138.0.0.0",
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7",
"Accept-Language": "zh-HK,zh-TW;q=0.9,zh;q=0.8,en;q=0.7,zh-CN;q=0.6,en-GB;q=0.5,en-US;q=0.4",
"Accept-Encoding": "gzip, deflate, br, zstd",
"Cache-Control": "max-age=0",
"Cookie": "SUB=_2AkMfzfnnf8NxqwFRmvoWz2vlaYhxyQDEieKpkQg8JRMxHRl-yT9yqnMJtRB6NE3XCAsFf68z8wyd0pilGGzauD4islBm; SUBP=0033WrSXqPxfM72-Ws9jqgMF55529P9D9WFY7of6GWKDycuJISJyAcL7; _s_tentry=passport.weibo.com; Apache=7174427033426.986.1754363600916; SINAGLOBAL=7174427033426.986.1754363600916; ULV=1754363600982:1:1:1:7174427033426.986.1754363600916:",
"DNT": "1",
"Sec-Ch-Ua": '"Not)A;Brand";v="8", "Chromium";v="138", "Microsoft Edge";v="138"',
"Sec-Ch-Ua-Mobile": "?0",
"Sec-Ch-Ua-Platform": '"Windows"',
"Sec-Fetch-Dest": "document",
"Sec-Fetch-Mode": "navigate",
"Sec-Fetch-Site": "none",
"Sec-Fetch-User": "?1",
"Upgrade-Insecure-Requests": "1"
})
if resp.status_code != 200:
await ctx.info(f"请求失败,状态码: {resp.status_code}")
return TextContent(type="text", text="获取微博热搜失败")
# 直接解析HTML内容
await ctx.info("正在解析HTML内容...")
html = resp.text
await ctx.info(f"HTML内容长度: {len(html)} 字符")
await ctx.info(f"HTML内容前1000字符: {html[:1000]}")
# 精准提取热搜关键词和热度
pattern = r'<tr.*?>\s*<td class="td-01.*?">.*?</td>\s*<td class="td-02">\s*<a [^>]*>(.*?)</a>\s*(?:<span>(.*?)</span>)?'
results = re.findall(pattern, html, re.DOTALL)
await ctx.info(f"找到 {len(results)} 条热搜数据")
if len(results) > 10:
await ctx.info(f"实际找到 {len(results)} 条,但可能只显示前10条")
hot_searches = []
for idx, (keyword, hot) in enumerate(results):
keyword = keyword.strip()
hot = hot.strip() if hot else ''
if hot:
hot_searches.append(f"{idx+1}. {keyword} [{hot}]")
else:
hot_searches.append(f"{idx+1}. {keyword}")
if not hot_searches:
await ctx.info("未能解析到热搜榜单")
return TextContent(type="text", text="未能获取到微博热搜榜单")
# 显示所有结果,如果太多则分段显示
if len(hot_searches) > 50:
result = f"微博热搜完整榜单(共{len(hot_searches)}条,显示前50条):\n" + "\n".join(hot_searches[:50])
result += f"\n\n... 还有 {len(hot_searches) - 50} 条未显示"
else:
result = f"微博热搜完整榜单(共{len(hot_searches)}条):\n" + "\n".join(hot_searches)
await ctx.info("已获取微博热搜榜单")
return TextContent(type="text", text=result)
except ImportError as e:
await ctx.info(f"缺少依赖库: {e}")
return TextContent(type="text", text="缺少httpx库,请安装: pip install httpx")
except Exception as e:
await ctx.info(f"获取微博热搜异常: {str(e)}")
await ctx.info(f"异常类型: {type(e).__name__}")
return TextContent(type="text", text=f"获取微博热搜时发生异常: {str(e)}")
if __name__ == "__main__":
import sys
if "mcp" in sys.argv:
# Configure MCP server with streamable-http transport
print("Starting MCP server with streamable-http transport...")
# MCP server will create its own FastAPI app with the /mcp endpoint
mcp.settings.host = "0.0.0.0"
mcp.run(transport="streamable-http")
else:
# Start FastAPI app for classic HTTP streaming
print("Starting FastAPI server for classic HTTP streaming...")
uvicorn.run("server:app", host="0.0.0.0", port=8000, reload=True)
版权声明: 如无特别声明,本文版权归 sshipanoo 所有,转载请注明本文链接。
(采用 CC BY-NC-SA 4.0 许可协议进行授权)
本文标题:《 MCP:模型上下文协议详解 》
本文链接:http://localhost:3015/ai/mcp.html
本文最后一次更新为 天前,文章中的某些内容可能已过时!

你愿意为你喜欢的事情付出多少!

