从“调包侠”到理解数学本质的探索
前馈神经网络学习笔记
配合
forward-weather.py代码使用 预计阅读时间:30 分钟
前言
接触深度学习有一段时间了,虽然能照着教程用 PyTorch 跑通代码,但对底层的原理一直是一知半解。最近花了一些时间系统地梳理了前馈神经网络(FNN)的知识,试图把数学公式和代码对应起来理解。
这篇文章主要记录了我对 FNN 的理解过程,尝试用通俗的语言(比如把神经元比作“小组长”)和代码实例把这些概念串联起来。如果你也是刚入门,希望这份笔记能对你有所帮助。
第一部分:神经网络的基本组成
常见神经网络类型
在深入研究前馈神经网络(FNN)的细节之前,我有必要先搞清楚它在整个神经网络家族中的位置。除了 FNN,我们经常还能听到 CNN、RNN、Transformer 等名字。它们有什么区别呢?
为了更好地理解,我们可以把不同的神经网络想象成不同工种的员工:
FNN (前馈神经网络)
全称:Feedforward Neural Network 特点:这是最基础的神经网络。它的结构就像一条单向的流水线,信息从输入层经过隐藏层直达输出层,中间没有回路,也不回头。它处理数据时是“一视同仁”的,不关心数据的空间结构(比如像素的上下左右关系)或时间顺序(比如句子的前后关系)。 应用:适合处理表格数据(比如根据年龄、收入预测消费能力)或简单的分类任务。
CNN (卷积神经网络)
全称:Convolutional Neural Network 特点:CNN 拥有一双“善于发现局部特征”的眼睛。它不像 FNN 那样一股脑把所有数据都连起来,而是用一个小的“窗口”(卷积核)在数据上滑动扫描。这让它非常擅长捕捉图像中的局部特征(比如猫的耳朵、车的轮子),而且不管这些特征出现在图片的哪个位置,它都能认出来(平移不变性)。 应用:图像识别、视频分析、医学影像诊断。
RNN (循环神经网络)
全称:Recurrent Neural Network 特点:RNN 自带“记忆”功能。在处理当前的信息时,它会参考上一步的信息。这就像我们在阅读时,理解当前这个词的意思,往往需要结合上下文。它的结构里有回路,可以让信息在时间维度上流动。 应用:语音识别、自然语言处理(NLP)、时间序列预测(比如股票走势)。
Transformer
全称:Transformer 特点:这是目前最强大的架构。它抛弃了 RNN 的循环结构,引入了“自注意力机制”(Self-Attention)。它能像指挥官一样,一眼看到全局,瞬间判断出输入序列中哪些部分是相关的,而不需要像 RNN 那样按顺序一个字一个字地读。这大大提高了并行计算的能力,也能捕捉到更长距离的依赖关系。 应用:大语言模型(如 GPT)、机器翻译、甚至开始在视觉领域(ViT)大展拳脚。
为了方便对比,我整理了一个简单的表格:
| 网络类型 | 核心特点 | 典型应用 | 形象比喻 |
|---|---|---|---|
| FNN | 全连接,无空间/时间结构,信息单向流 | 表格数据、简单分类 | 流水线工人:机械地处理传送带上的零件。 |
| CNN | 局部连接,参数共享,提取空间特征 | 图像识别 (CV) | 安检员:拿着扫描仪逐行扫描,寻找可疑特征。 |
| RNN | 有记忆,处理序列数据 | 语音识别、文本生成 | 速记员:听写时不仅听当前词,还记得前面说了什么。 |
| Transformer | 自注意力机制,并行计算,捕捉长距离依赖 | 大模型 (LLM)、翻译 | 指挥官:一眼看全局,瞬间判断出哪些词之间有关系。 |
现在的地位: 虽然现在很少单独用纯 FNN 做复杂的视觉或 NLP 任务,但它并没有过时。它通常作为复杂网络(比如 Transformer 的 MLP 层)的基础组件存在。
什么是前馈神经网络?
搞清楚了定位,我们再把目光聚焦到最基础的 前馈神经网络(FNN) 上。
所谓的“前馈”(Feedforward),是指信息的传播方向是单一的、向前的。
- 结构上:它是一个有向无环图(DAG)。信号从输入层出发,逐层经过隐藏层,最终抵达输出层。
- 逻辑上:网络中不存在“回路”或“反馈”。第 $i$ 层的输出只能作为第 $i+1$ 层的输入,绝不会反过来影响第 $i-1$ 层,也不会直接影响自己。
这就像一条严格管理的工业流水线:
- 原材料(输入)被放到传送带上。
- 经过一个个加工车间(隐藏层),每个车间只负责处理上一个车间送来的半成品,处理完立刻送往下个车间。
- 车间工人绝不会把零件退回给上一步,也不会拿着零件在车间里转圈圈。
- 最终,成品(输出)从流水线末端下线。
这种“不走回头路”的特性,使得 FNN 本质上是一个静态的函数映射:给定一个输入 $x$,它永远会产生固定的输出 $y$(假设参数不变)。这与具有记忆功能、输出依赖于历史状态的 RNN 形成了鲜明对比。
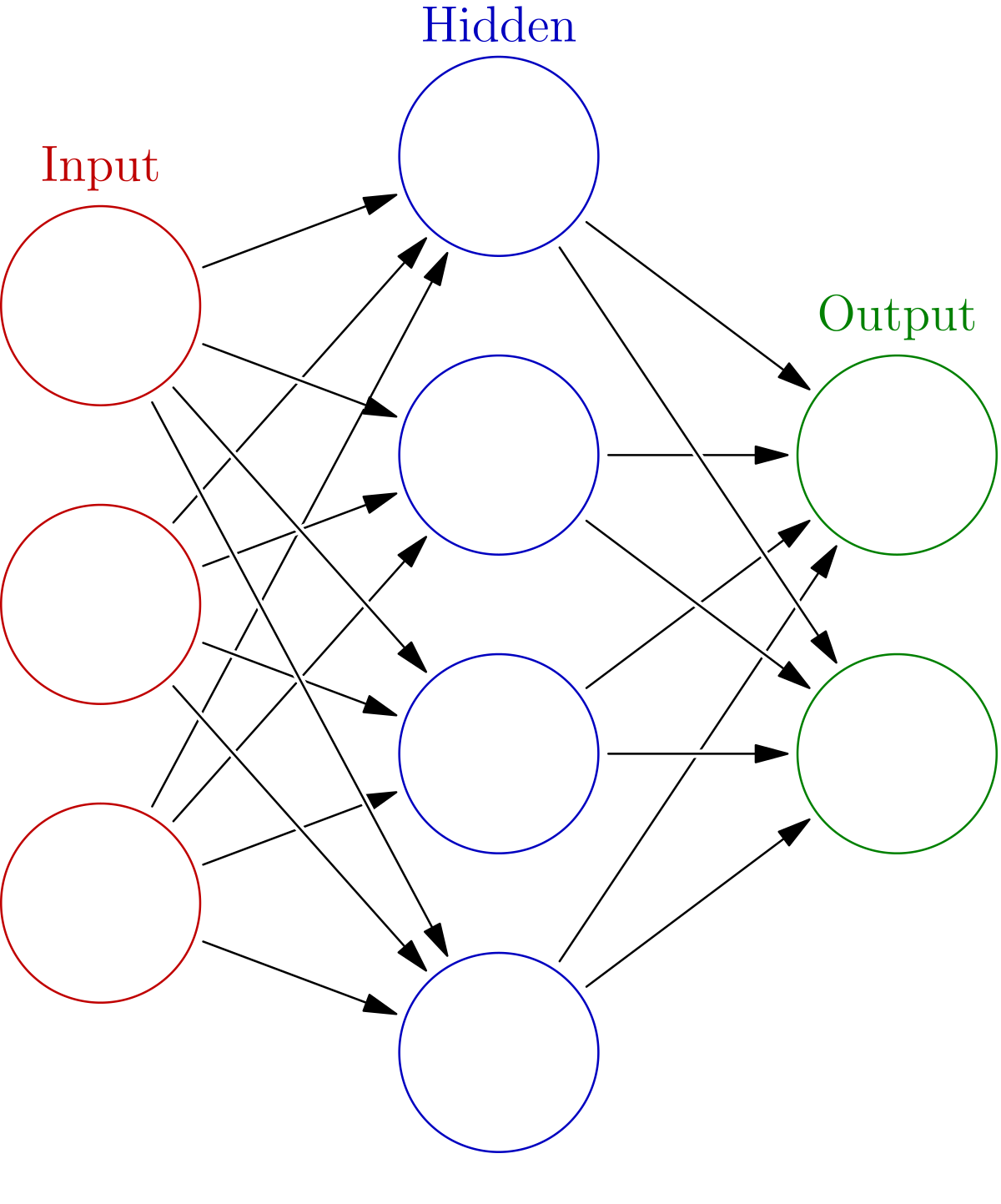 图:一个典型的前馈神经网络结构,包含输入层、隐藏层和输出层。
图:一个典型的前馈神经网络结构,包含输入层、隐藏层和输出层。
神经元
神经网络的基本单元是神经元(Neuron)。为了方便理解,我们可以把它想象成公司里的一个小组长。
这个小组长接收来自下属(输入 $x$)的汇报,根据每个下属的可信度(权重 $W$)进行综合判断,最后决定是否向上级汇报(激活输出)。
 图:人工神经元的数学模型。
图:人工神经元的数学模型。
数学公式: \(y = \sigma(\sum_{i=1}^{n} w_i x_i + b)\)
或者向量形式: \(y = \sigma(W^T x + b)\)
这里的每一个组件都有深刻的现实意义:
- 输入 ($x$):外界的信号。比如我们要预测房价,输入就是“面积”、“地段”、“房龄”。
-
权重 ($W$):信号的重要性。
- 如果“面积”的权重很大,说明面积对房价影响很大。
- 如果“房龄”的权重是负数,说明房龄越老,房价越低。
- 学习的过程,本质上就是调整这些权重,找到最符合现实规律的参数组合。
-
偏置 ($b$):门槛或基准。
- 比如一个乐观的人(偏置高),即使没有好消息(输入为0),他也倾向于开心(激活)。
- 一个悲观的人(偏置低),需要非常强烈的正面刺激才能开心。
- 加权求和 ($z = W^T x + b$):综合评分。小组长把所有信息汇总,算出一个总分。
-
激活函数 ($\sigma$):非线性的决策。
- 如果没有激活函数,小组长只是机械地传话。
- 有了激活函数,小组长可以做复杂的决定:比如“只有总分超过60分,我才向上级汇报,否则就当没听见”。
激活函数
这是神经网络中最关键,也最容易被初学者误解的概念。为什么我们必须在每一层后面加一个激活函数?
核心问题:线性的局限性
如果没有激活函数,无论神经网络有多少层,它本质上都只是一个线性模型。
让我们看一个简单的数学推导: 假设第一层的计算是 $y_1 = W_1 x + b_1$(线性变换)。 假设第二层的计算是 $y_2 = W_2 y_1 + b_2$。
如果我们直接把 $y_1$ 代入 $y_2$: \(y_2 = W_2 (W_1 x + b_1) + b_2 = (W_2 W_1) x + (W_2 b_1 + b_2)\)
请注意,$(W_2 W_1)$ 依然是一个矩阵,$(W_2 b_1 + b_2)$ 依然是一个向量。这意味着,两层线性网络等价于一层线性网络。哪怕你堆叠一万层,它也只能画出一条直线(或平面),无法解决像“异或(XOR)”或者“环形分类”这样简单的非线性问题。
激活函数的作用,就是引入非线性因素。它让神经网络不再是简单的直线叠加,而是能够发生“弯曲”和“折叠”,从而拟合任意复杂的曲线。
常见激活函数深度解析
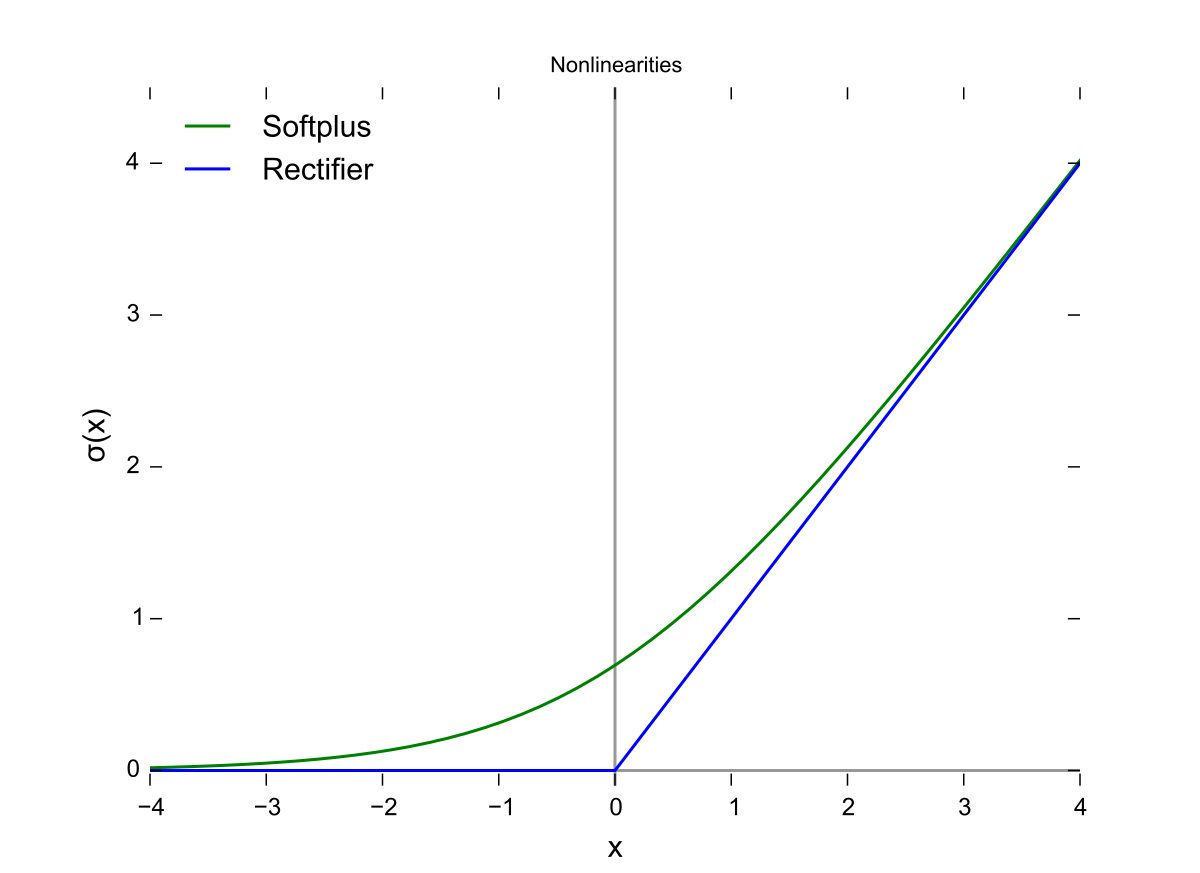 图:ReLU(蓝线)与 Softplus(绿线)函数图像。
图:ReLU(蓝线)与 Softplus(绿线)函数图像。
1. Sigmoid 函数:模拟生物神经元的“饱和” \(\sigma(x) = \frac{1}{1 + e^{-x}}\)
- 特性:它将任意实数压缩到 $(0, 1)$ 区间。
- 直观理解:它很像一个“软开关”。输入很小时输出接近 0,输入很大时输出接近 1,中间有一个平滑的过渡区。
- 局限性:注意看图像的两端,曲线变得非常平缓。这意味着在反向传播时,梯度(导数)几乎为 0。这就是著名的梯度消失问题——深层网络的信号传不到前面,导致无法训练。因此,现代深层网络(中间层)很少使用 Sigmoid,通常只用于二分类任务的最终输出层(表示概率)。
2. ReLU (Rectified Linear Unit):简单即是美 \(f(x) = \max(0, x)\)
- 特性:输入大于 0 时,直接输出原值;输入小于 0 时,输出 0。
-
直观理解:这是一个折页(Hinge)。它非常简单,但极其有效。
- 解决梯度消失:在 $x > 0$ 的区域,导数恒为 1,梯度可以无损地传回前面的层。
- 稀疏激活性:它会强制一部分神经元输出为 0(不激活)。这模拟了生物大脑的节能机制——同一时刻只有少部分神经元在工作。这种稀疏性让模型更具鲁棒性。
- 地位:目前深度学习中最主流的激活函数。虽然它在 $x=0$ 处不可导(数学上的小瑕疵),但在工程实践中完全不是问题。
第二部分:神经网络的功能本质
如果把神经网络看作一个整体,它在做什么?
通用逼近定理 (Universal Approximation Theorem) 告诉我们:
一个包含足够多神经元的单隐层前馈神经网络,可以以任意精度逼近任何连续函数。
这听起来很抽象,我们举个例子:
想象你要根据“身高”和“体重”来判断一个人的“体型”(瘦、胖、标准)。
- 这背后的规律可能非常复杂,不是简单的“身高-体重=105”就能概括的。
- 它可能是一条弯弯曲曲的界线。
- 神经网络的作用,就是通过大量的样本训练,自动“描”出这条复杂的界线。
它本质上是一个万能的函数拟合器。只要给它足够的数据,它就能模仿出任何输入到输出的映射关系。
第三部分:实战演练
我们将构建一个模型,根据 [云量, 风速, 湿度] 预测 [是否下雨]。
数据准备
下面是数据准备的完整代码,每一步都配有详细注释,帮助你理解每一行的作用:
import torch # 导入 PyTorch 主库
import torch.nn as nn # 导入神经网络模块
import torch.optim as optim # 导入优化器模块
import numpy as np # 导入 numpy 用于数据处理
# 设定随机种子,保证每次运行结果一致,方便复现
torch.manual_seed(42) # PyTorch 随机种子
np.random.seed(42) # numpy 随机种子
num_samples = 1000 # 样本数量,模拟 1000 天的天气
# 生成特征:模拟 1000 天的天气数据
# 云量、风速、湿度都在 0 到 100 之间
cloud = np.random.randint(0, 100, num_samples) # 随机生成云量
wind = np.random.randint(0, 100, num_samples) # 随机生成风速
humidity = np.random.randint(0, 100, num_samples) # 随机生成湿度
# 生成标签:定义真实的下雨规律
# 假设规律是:(湿度 + 云量) > 风速 * 1.2 时,就会下雨
# 这是一个非线性的规则,我们看看神经网络能不能自己学会它
labels = ((humidity + cloud) > wind * 1.2).astype(np.float32) # 满足条件为1,否则为0
# 数据预处理:归一化是关键!
# 将数据压缩到 [0,1] 区间。
# 例子:这就好比考试,有的科目满分100,有的满分150。如果不统一换算成百分制,总分就会被满分高的科目主导。
# 神经网络也是一样,如果风速是 0-1000,云量是 0-1,网络会认为风速更重要。归一化让所有特征站在同一起跑线上。
X = np.stack([cloud, wind, humidity], axis=1).astype(np.float32) / 100.0 # 合并特征并归一化
y = labels.reshape(-1, 1) # 标签变成列向量
X_tensor = torch.from_numpy(X) # 转为 PyTorch 张量
y_tensor = torch.from_numpy(y) # 转为 PyTorch 张量
上面代码完成了数据的生成、标签的构造和归一化处理。每一步都很关键,尤其是归一化,否则神经网络训练会很困难。
搭建网络结构
下面是神经网络结构的定义,每一行都配有详细注释:
class WeatherNet(nn.Module): # 定义一个继承自 nn.Module 的神经网络类
def __init__(self):
super(WeatherNet, self).__init__() # 初始化父类
# 第一层:特征提取层
# 输入 3 个特征,输出 8 个新特征
# 升维有助于把纠缠在一起的数据分开
self.fc1 = nn.Linear(3, 8) # 全连接层1:输入3维,输出8维
# 第二层:决策输出层
# 将8个中间特征汇总,输出1个结果(下雨概率)
self.fc2 = nn.Linear(8, 1) # 全连接层2:输入8维,输出1维
# 激活函数:把结果压缩到0-1之间,表示概率
self.sigmoid = nn.Sigmoid() # Sigmoid激活函数
def forward(self, x): # 前向传播定义
# 1. 第一层思考:线性分析 + ReLU筛选
# ReLU 就像一个过滤器,把负面的、不重要的信号过滤掉(置为0)
x = torch.relu(self.fc1(x))
# 2. 第二层思考:综合判断 + Sigmoid输出概率
x = self.sigmoid(self.fc2(x))
return x # 返回最终输出
model = WeatherNet() # 实例化模型
上面代码定义了一个两层的前馈神经网络,结构简单但足以拟合本例的非线性规律。
深度思考:为什么要随机初始化权重? 想象一下,如果公司里所有员工的初始想法都一模一样(权重全为0),那么无论怎么开会讨论(训练),大家的进步方向都是一样的,最后整个公司就等于只有一个人在工作。 随机初始化就是让每个神经元一开始就有不同的“性格”和“偏好”,这样在训练过程中,它们才能分工合作,分别关注不同的特征(有的关注风,有的关注云)。
第四部分:模型优化
有了网络架构(身体)和数据(经验),我们还需要一个机制来让网络真正“学”到东西。这个过程在数学上被称为优化(Optimization)。
简单来说,优化的目标就是找到一组最完美的权重参数 ($W$ 和 $b$),使得模型预测的结果和真实结果之间的误差(Loss)最小。
损失函数:衡量错误的尺子
首先,我们需要定义什么是“错误”。这就是损失函数(Loss Function)的作用。
损失函数的选择对模型训练效果影响很大。这里我们用二元交叉熵,适合二分类问题:
# 二元交叉熵 (Binary Cross Entropy)
criterion = nn.BCELoss() # 定义损失函数为二元交叉熵
BCELoss 会衡量模型输出概率与真实标签之间的差距,输出越接近真实标签,损失越小。
为什么不用 MSE(均方误差)?
- MSE:适合预测具体的数值(比如预测气温是 25.5 度)。
-
交叉熵:适合分类问题(比如预测是猫还是狗)。
- 例子:如果正确答案是 1(下雨),模型预测是 0.01(不下雨)。
- MSE 算出来的误差比较小(平缓)。
- 交叉熵算出来的误差会非常大(陡峭),因为它包含对数运算。这就像老师严厉地批评:“错得离谱!必须马上改!”这能让模型学得更快。
梯度下降:迷雾中的下山路
有了评分标准,我们怎么调整参数来提高分数呢?这里就要用到梯度下降(Gradient Descent)算法。
我们可以把损失函数想象成一座连绵起伏的山脉,山的高度代表误差的大小。我们的目标是找到山谷的最低点(误差最小点)。
但难点在于,我们就像被蒙住了双眼(或者身处浓雾之中),看不清整座山的全貌。我们唯一能做的,就是用脚探一探周围的地形,感觉到哪边是下坡,就往哪边迈一步。
- 梯度:就是脚下最陡峭的下坡方向。
- 学习率(Learning Rate):就是迈出的步子大小。
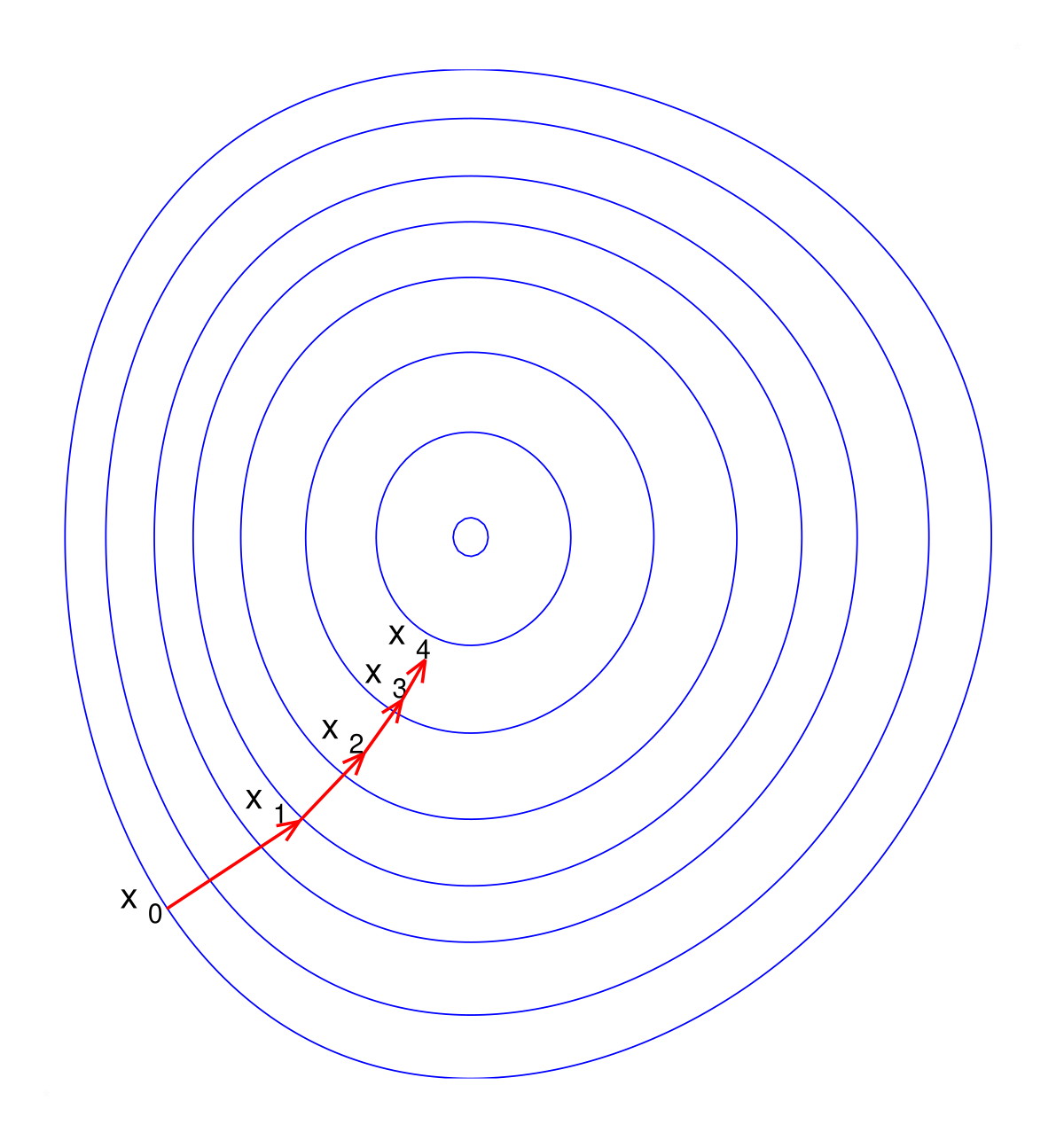 图:梯度下降示意图。我们沿着梯度的反方向(下坡方向)更新参数,最终到达最低点。
图:梯度下降示意图。我们沿着梯度的反方向(下坡方向)更新参数,最终到达最低点。
优化器:更聪明的下山策略
最基础的梯度下降(SGD)有时候比较笨,容易卡在半山腰的小坑里(局部最优),或者在平地上走得太慢。为了解决这些问题,人们发明了各种优化器(Optimizer)。
优化器决定了参数如何更新。Adam 是目前最常用的优化器之一:
# Adam (Adaptive Moment Estimation)
optimizer = optim.Adam(model.parameters(), lr=0.01) # Adam 优化器,学习率0.01
Adam 优化器能自适应调整每个参数的学习率,通常收敛更快。
- SGD (随机梯度下降):朴实无华,每一步都只看脚下,哪边陡走哪边。
- Momentum (动量):带个滑板下山。利用惯性,遇到小坑能冲过去,平地上也能滑得快。
- Adam:不仅带滑板,还带了智能导航。它会根据地形自动调整步子大小。陡峭的地方步子小一点(怕摔倒),平坦的地方步子大一点(加速)。这是目前最常用的优化器。
第五部分:模型训练
下面是模型训练的完整流程,每一步都配有详细注释:
epochs = 1000 # 训练轮数
loss_history = [] # 用于记录每一轮的损失
for epoch in range(epochs):
# 1. 前向传播 (Forward Pass)
# 学生做题:根据当前的理解,给出答案
outputs = model(X_tensor) # 用当前模型预测输出
# 2. 计算损失 (Compute Loss)
# 老师批改:对比标准答案,计算考了多少分(误差)
loss = criterion(outputs, y_tensor) # 计算损失
# 3. 梯度清零 (Zero Gradients)
# 忘掉上一轮的纠结,重新开始思考
optimizer.zero_grad() # 梯度清零
# 4. 反向传播 (Backward Pass)
# 核心中的核心!找原因:
# 为什么错了?是哪个知识点(权重)没掌握好?
# 责任分配:谁导致了错误,谁就要大幅度修改。
loss.backward() # 反向传播,计算梯度
# 5. 参数更新 (Parameter Update)
# 改正错误:根据反向传播的结果,调整自己的理解(权重)
optimizer.step() # 更新参数
if (epoch + 1) % 100 == 0:
print(f'Epoch [{epoch+1}/{epochs}], Loss: {loss.item():.4f}') # 每100轮打印一次损失
上面代码完整展示了神经网络训练的五个核心步骤。
深入反向传播 (Backpropagation)
反向传播不仅仅是求导,它是一种高效的责任分配机制。
想象一个工厂流水线生产出了次品。
- 我们从最后一道工序开始倒查。
- 如果是最后一道工序的问题,就调整最后一道工序的参数。
- 如果是原材料的问题,就追溯到源头。
- 反向传播就是通过链式法则,精确地计算出每一个神经元对最终错误的贡献大小,然后针对性地进行修改。
第六部分:过拟合与正则化
在实际教学中,我们最怕学生死记硬背。
什么是过拟合?
如果模型参数太多(脑容量太大),或者训练时间太长(刷题太多),模型可能会把训练数据里的噪声(比如某次测量的误差)也当成规律记下来。
- 表现:平时作业(训练集)全对,一考试(测试集)就挂。
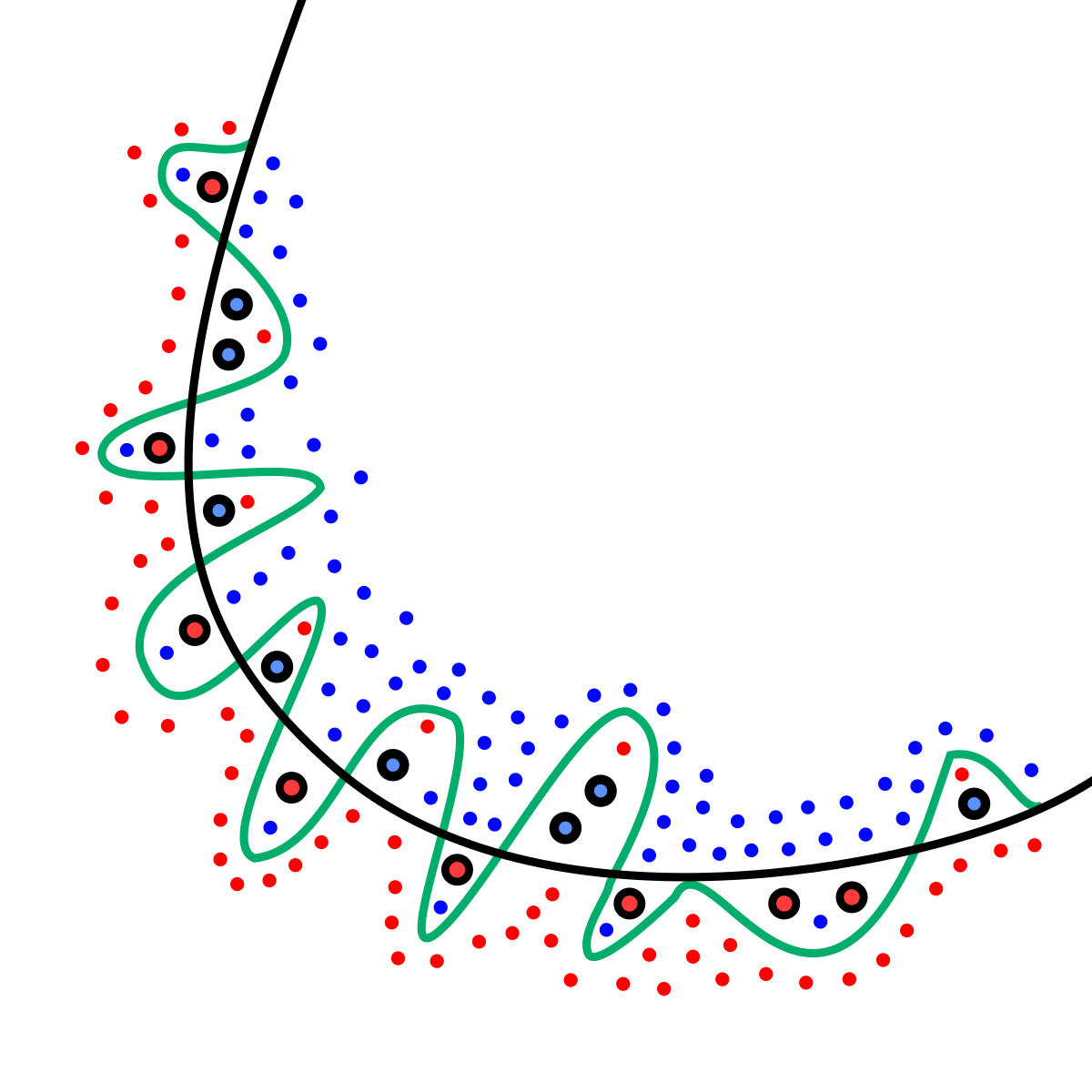 图:过拟合示意图。绿线(过拟合)为了拟合所有噪点而变得扭曲,黑线(理想模型)则抓住了主要规律。
图:过拟合示意图。绿线(过拟合)为了拟合所有噪点而变得扭曲,黑线(理想模型)则抓住了主要规律。
对抗过拟合的武器
-
Dropout:随机旷课。
- 在训练时,随机让一部分神经元“休息”。
- 这强迫其他神经元必须独立承担责任,不能依赖某个“学霸”神经元。
- 结果:整个团队(网络)变得更加鲁棒,抗干扰能力更强。
-
L2 正则化 (Weight Decay):奥卡姆剃刀。
- 在损失函数里加一项惩罚,惩罚那些数值过大的权重。
- 原理:如无必要,勿增实体。我们倾向于用更简单的模型(权重更小、更平滑)来解释数据。
-
早停 (Early Stopping):适可而止。
- 当发现考试成绩(验证集 Loss)不再提高甚至开始下降时,立刻停止复习(训练)。
第七部分:模型评估与测试
最后是模型评估和单样本测试,下面是详细注释版:
with torch.no_grad(): # 预测时不需要计算梯度,节省显存和计算资源
predictions = model(X_tensor) # 用模型对全部数据做预测
predicted_classes = (predictions > 0.5).float() # 概率大于0.5判为1,否则为0
accuracy = (predicted_classes == y_tensor).float().mean() # 计算准确率
print(f'Accuracy: {accuracy.item() * 100:.2f}%') # 打印准确率
# 测试单个样本
# 归一化后的输入:云80, 风10, 湿70 -> 0.8, 0.1, 0.7
test_sample = torch.tensor([[0.8, 0.1, 0.7]]) # 构造测试样本
# 规则:0.7 + 0.8 > 0.1 * 1.2 (1.5 > 0.12) -> 应为 1 (下雨)
pred = model(test_sample).item() # 得到预测概率
print(f"Test Prediction (Cloud=80, Wind=10, Hum=70): {pred:.4f} ({'Rain' if pred>0.5 else 'No Rain'})") # 打印预测结果
这样你可以清楚看到每一步的作用和原理。
总结:一点感悟
回顾整个学习过程,最让我震撼的是:我们并没有编写任何显式的 if-else 规则来判断天气,只是搭建了一个架构,设定了一个目标,然后让机器自己去“学”。这就是 Andrej Karpathy 提到的 Software 2.0 的核心思想吧——程序员不再编写具体的逻辑,而是编写学习逻辑的逻辑。
还有一些没想通的地方
虽然大体流程跑通了,但我还有一些疑问,留作以后继续探索:
- 局部最小值:梯度下降就像下山,但如果被困在山腰的湖泊里(局部最优)怎么办?现在的优化器真的能完美解决吗?
- 深度 vs 宽度:到底是把网络做深一点好,还是做宽一点好?它们在本质上有什么区别?
这次复盘就先到这里,希望能对同样在入门路上的朋友有一点点启发。
版权声明: 如无特别声明,本文版权归 sshipanoo 所有,转载请注明本文链接。
(采用 CC BY-NC-SA 4.0 许可协议进行授权)
本文标题:《 机器学习基础系列——前馈神经网络 》
本文链接:http://localhost:3015/ai/%E5%89%8D%E9%A6%88%E7%A5%9E%E7%BB%8F%E7%BD%91%E7%BB%9C.html
本文最后一次更新为 天前,文章中的某些内容可能已过时!

你愿意为你喜欢的事情付出多少!
